微调Mobius 12B base模型记录
目录
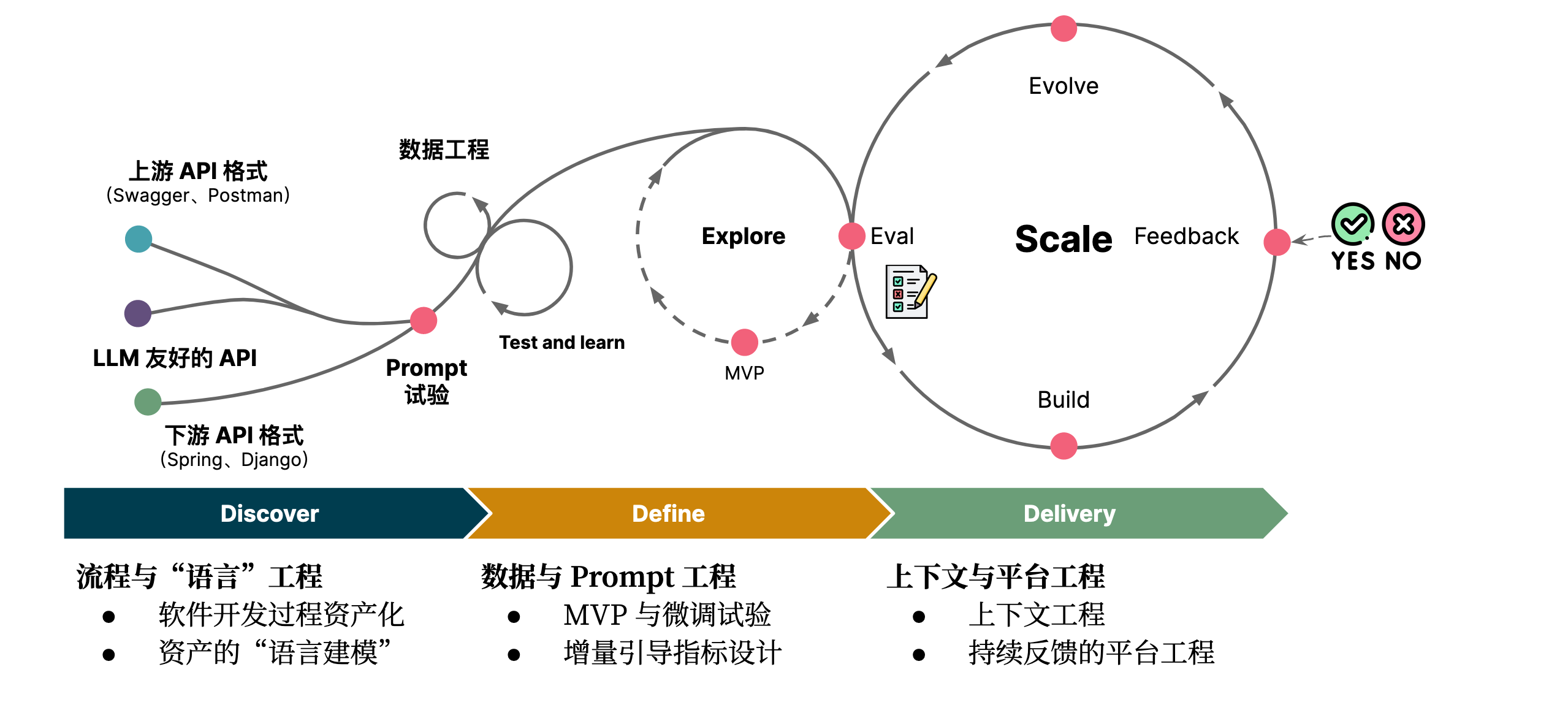

微调Mobius 12B base模型,会涉及以下步骤。
- 安装必要的库。如果你还没安装,首先需要安装Hugging Face的Transformers库,pip install transformers`来进行安装。
- 加载预训练的模型和分词器。如我之前提到的,你可以用以下代码加载模型和分词器:
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xiaol/Mobius-12B-base")
model = AutoModel.from_pretrained("xiaol/Mobius-12B-base")准备你的数据集。你需要有一个目标任务的数据集来进行模型的微调。这个数据集需要和你的模型要解决的任务相关。例如,如果你想做文本分类,你就需要有标签的文本数据。
微调一个预训练模型,如Mobius 12B base模型,首先你需要有一个特定任务的数据集。根据任务不同,你可能需要准备不同类型的数据集。以下是一些常见任务的数据集例子:
- 文本分类:例如情感分析、主题分类等任务,你需要准备带有类别标签的文本数据。例如,你可能需要一个句子库和与之对应的标签列表。
- 序列标注:例如命名实体识别、词性标注等任务,你需要准备带有单词级别标签的句子。
- 问答:对于问答任务,你需要一组问题和对应的答案。
另外,为了更好的完成微调,你需要注意以下关键事项:
正负样本比例:如果你在进行分类任务时,保持正负样本比例的平衡是很重要的,否则可能引导模型偏向多数样本,导致预测效果偏差。
数据质量:模型的性能在很大程度上取决于数据的质量。数据应尽量准确无误,噪声少,且能够代表实际需求中需要处理的数据。
数据预处理:去除噪声(如无关的标点符号),统一文本格式(如小写化),去除停用词等预处理步骤可以提高你模型的性能。另外,由于模型对输入长度有限制,因此可能需要对长文本进行适当的截断或分割。
验证集和测试集:确保你有独立的验证集和测试集来适当评估模型性能。这些数据集不应参与训练过程。
数据标注:如果你的任务需要标注(例如,序列标注),请确保标签的一致性和准确性。
- 文本分词与数据预处理。使用加载的分词器对你的数据集进行分词操作。例如,你可以参考以下代码将文本转化为模型可以接受的输入形式:
inputs = tokenizer("Hello, world!", return_tensors="pt") 在`return_tensors="pt"`中,"pt"是指PyTorch张量。这会返回一个包含了输入的id,mask等信息的字典。- 微调模型。现在你可以在你的数据集上微调模型了。你需要为你的微调任务定义一个模型,这个模型需要有一个适合你目标任务的头部,例如,一个文本分类头或者一个序列标注头。
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results", # 输出目录
num_train_epochs=3, # 总共训练的周期(epoch)数
per_device_train_batch_size=16, # 每个gpu的训练batch大小
per_device_eval_batch_size=64, # 每个gpu的评价batch大小
warmup_steps=500, # warmup步数
weight_decay=0.01, # 权重衰减
)
trainer = Trainer(
model=model, # 微调的模型
args=training_args, # 训练参数
compute_metrics=compute_metrics, # 用于计算和记录评估指标的函数
train_dataset=train_dataset, # 训练数据集
eval_dataset=val_dataset, # 验证数据集
)
trainer.train()评估模型。训练完成之后,你需要在验证集或者测试集上评估你的模型,以了解微调之后模型的表现。
模型保存。当你对模型的表现满意时,你可以保存模型以供后续使用
model.save_pretrained("./path_to_save") # 保存模型
tokenizer.save_pretrained("./path_to_save") # 保存分词器