timesFM使用教程
TimesFM安装
TimesFM(Time Series Foundation Model,时间序列基础模型)是谷歌研究院开发的一种用于时间序列预测的预训练模型。
论文:一种仅用于时间序列预测的解码器基础模型,即将在2024年国际机器学习大会(ICML)中发表。 谷歌研究博客 Hugging Face检查点仓库 此仓库包含了加载公共TimesFM检查点和运行模型推理的代码。请访问我们的Hugging Face检查点仓库以下载模型检查点。
这不是一个官方支持的谷歌产品。
检查点 timesfm-1.0-200m timesfm-1.0-200m 是第一个公开的模型检查点:
- 对于最高512个时间点的上下文长度和任何范围长度的单变量时间序列预测进行性能,带有可选的频率指示器。
- 它专注于点预测,不支持概率预测。我们实验性地提供了分位数头部,但在预训练后没有进行校准。
- 它要求上下文是连续的(即没有“洞”),且上下文和范围具有相同的频率。
1 基准测试
请参考我们在扩展基准测试和长期基准测试上的结果表。
请参阅位于 experiments/ 中相应基准测试目录的 README 文件,获取在相应基准测试中运行TimesFM的说明。
2 安装
为了调用TimesFM,我们有两个环境文件。在timesfm中,对于GPU安装(假设已经设置了CUDA 12),你可以通过以下命令从基础文件夹中创建conda环境 tfm_env:
conda env create --file=environment.yml对于CPU设置,请使用:
conda env create --file=environment_cpu.yml来创建环境。随后执行
conda activate tfm_env
pip install -e .来安装包。
注意:
- 运行所提供的基准测试将需要额外的依赖关系。请改用 experiments 下的环境文件。
- 依赖关系 lingvo 不支持ARM架构,且代码不工作于搭载苹果硅片的机器上。我们意识到这个问题,并正在寻求解决方案。请继续关注。
3 使用方法
初始化模型并加载检查点。 然后可以如下加载基类:
import timesfm
tfm = timesfm.TimesFm(
context_len=<context>,
horizon_len=<horizon>,
input_patch_len=32,
output_patch_len=128,
num_layers=20,
model_dims=1280,
backend=<backend>,
)
tfm.load_from_checkpoint(repo_id="google/timesfm-1.0-200m")注意加载200m模型固定了四个参数
- input_patch_len=32,
- output_patch_len=128,
- num_layers=20,
- model_dims=1280,
这里的 context_len 可以设置为模型的最大上下文长度。它需要是 input_patch_len,即 32 的倍数。你可以向 tfm.forecast() 函数提供更短的序列,模型会进行处理。目前,模型处理的最大上下文长度为 512,这可以在后续版本中增加。输入的时间序列可以有任何上下文长度。如果需要,填充/截断将由推理代码处理。
范围长度可以设置为任何值。我们建议将其设置为您在预测任务中可能需要的最大范围长度。我们通常建议范围长度小于等于上下文长度,但这不是函数调用中的要求。
backend 是 “cpu”、“gpu” 或 “tpu” 中的一个,区分大小写。
执行推理 我们提供了API,可以从数组输入或pandas dataframe进行预测。两种预测方法都需要(1)输入时间序列上下文,(2)以及它们的频率。请查阅 tfm.forecast() 和 tfm.forecast_on_df() 函数的文档获取详细说明。
尤其是关于频率,TimesFM期望一个在 {0, 1, 2} 中取值的分类指示符:
- 0(默认):高频、长范围时间序列。我们建议将其用于每日粒度以下的时间序列。
- 1:中频时间序列。我们建议将其用于每周和每月数据。
- 2:低频、短范围时间序列。我们建议将其用于每月以外的任何数据,例如季度或年度。
这个分类值应该直接与数组输入一起提供。对于dataframe输入,我们将传统的频率字母编码转换为我们预期的分类,即
- 0: T, MIN, H, D, B, U
- 1: W, M
- 2: Q, Y
请注意,您不必严格遵循我们的推荐。虽然这是我们在模型训练期间的设置,我们期望它能提供最佳的预测结果,但您也可以将频率输入视为一个自由参数,并根据您的具体使用案例进行修改。
示例:
- 使用数组输入,频率分别设置为低、中、高。
import numpy as np
forecast_input = [
np.sin(np.linspace(0, 20, 100)),
np.sin(np.linspace(0, 20, 200)),
np.sin(np.linspace(0, 20, 400)),
]
frequency_input = [0, 1, 2]
point_forecast, experimental_quantile_forecast = tfm.forecast(
forecast_input,
freq=frequency_input,
)- 使用pandas dataframe,频率设置为"M"每月。
import pandas as pd
# 例如 input_df 是
# unique_id ds y
# 0 T1 1975-12-31 697458.0
# 1 T1 1976-01-31 1187650.0
# 2 T1 1976-02-29 1069690.0
# 3 T1 1976-03-31 1078430.0
# 4 T1 1976-04-30 1059910.0
# ... ... ... ...
# 8175 T99 1986-01-31 602.0
# 8176 T99 1986-02-28 684.0
# 8177 T99 1986-03-31 818.0
# 8178 T99 1986-04-30 836.0
# 8179 T99 1986-05-31 878.0
forecast_df = tfm.forecast_on_df(
inputs=input_df,
freq="M", # 每月
value_name="y",
num_jobs=-1,
)首先,确保你已经激活了新创建的环境timesfm。如果未创建,请先运行以下命令创建并激活环境:
bash
conda create -n timesfm python=3.10
conda activate timesfm接下来,你可以按照如下步骤逐一安装环境中的依赖。注意,对于某些库,可能需要先确认是否存在必要的系统依赖或者兼容性问题,尤其是那些包含本地扩展或系统特定二进制文件的库:
- 安装基本工具库:
pip install jupyterlab- 安装Hugging Face库:
由于Hugging Face Hub有时需要CLI支持,因此使用[cli]后缀确保所有必要的CLI工具都被安装:
pip install huggingface_hub[cli]- 安装特定的数据科学与机器学习库:
对于其他库,以及特定于机器学习和数据处理的库,如utilsforecast、paxml、einshape,可以直接逐个安装:
pip install utilsforecast
pip install paxml # 报错 lingvo 无兼容的pip安装包
pip install einshape- 安装JAX与CUDA支持:
由于JAX对CUDA的支持可能需要指定具体版本,这里提供一个通用的指令范例。务必根据你的硬件配置和需求,选择适合你CUDA版本的JAX安装方法。为了使用CUDA,你需要确认已经正确安装了CUDA Toolkit,且版本与JAX要求相符:
pip install "jax[cuda12_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html请注意,为了正确安装支持CUDA的JAX版本,这里指定了一个额外的资源链接。如果你的CUDA版本不是12,请适当调整上述命令中的cuda12_pip部分。
- 安装
praxis:
最后,你可以尝试安装praxis。根据你之前遇到的问题描述,praxis可能依赖于特定版本的包,如果在安装过程中遇到兼容性问题或依赖冲突,你可能需要查找更具体的安装指南或文档:
pip install praxis完成上述步骤后,你应该已经成功安装了所有依赖,并准备好开始你的项目。
windows手动安装lingvo
pushd D:\Software\miniconda3\envs\timesfm\lingvo
git clone https://github.com/tensorflow/lingvo
set JAVA_HOME=D:\Software\rar\other\jdk-11.0.9.1+1
set PATH=%JAVA_HOME%\bin;%PATH%
java -version
echo %JAVA_HOME%
"D:\Software\miniconda3\envs\timesfm\lingvo\bazel.exe"
bazel build -c opt //lingvo:trainer报错
改为 bazel build -c opt //lingvo:trainer --experimental_repo_remote_exec
set TENSORFLOW_LIB_PATH=d:\software\miniconda3\envs\timesfm\lib\site-packages\tensorflow-2.13.1-py3.10-win-amd64.egg
"D:\Software\miniconda3\envs\timesfm\lingvo\lingvo\repo.bzl"
_find_tf_include_path
_find_tf_lib_path
exec_result = repo_ctx.execute(
[
"d:\\software\\miniconda3\\envs\\timesfm\\python.exe",
D:/software/miniconda3/envs/timesfm/lingvo/lingvo/core/ops/BUILD:104:22: //lingvo/core/ops:ml_perf_subword_op depends on @@icu//:common in repository @@icu which failed to fetch. no such package '@@icu//': java.io.IOException: Error downloading [https://storage.googleapis.com/mirror.tensorflow.org/github.com/unicode-org/icu/archive/release-64-2.zip, https://github.com/unicode-org/icu/archive/release-64-2.zip] to C:/users/administrator/_bazel_administrator/vyxpmpa2/external/icu/temp2962938191340349563/release-64-2.zip: Checksum was 10cd92f1585c537d937ecbb587f6c3b36a5275c87feabe05d777a828677ec32f but wanted dfc62618aa4bd3ca14a3df548cd65fe393155edd213e49c39f3a30ccd618fc27
ERROR: Analysis of target '//lingvo:trainer' failed; build aborted: Analysis failed
INFO: Elapsed time: 72.430s, Critical Path: 0.03s
INFO: 1 process: 1 internal.
ERROR: Build did NOT complete successfully
(timesfm) D:\Software\miniconda3\envs\timesfm\lingvo> bazel clean --expunge
INFO: Starting clean.
(timesfm) D:\Software\miniconda3\envs\timesfm\lingvo> bazel build -c opt //lingvo:trainer --experimental_repo_remote_exec
---
pip install tensorflow==2.9.0
pip install apache-beam backports.lzma etils graph-compression-google-research jupyter jupyter_http_over_ws matplotlib model-pruning-google-research Pillow scikit-learn sentencepiece sympy tensorflow-datasets tensorflow-hub tensorflow-probability tensorflow-text
bazel build -c opt //lingvo:trainer --experimental_repo_remote_exec
INFO: Analyzed target //lingvo:trainer (4 packages loaded, 7914 targets configured).
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/core/ops/BUILD:43:13: Copying Execution Dynamic Library failed: missing input file '@@tensorflow_solib//:tensorflow_solib/libtensorflow_framework.so.2'
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/tasks/car/ops/BUILD:36:13: Copying Execution Dynamic Library failed: missing input file '@@tensorflow_solib//:tensorflow_solib/libtensorflow_framework.so.2'
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/tools/BUILD:163:17: Copying Execution Dynamic Library [for tool] failed: missing input file '@@tensorflow_solib//:tensorflow_solib/libtensorflow_framework.so.2'
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/tools/BUILD:163:17: Copying Execution Dynamic Library [for tool] failed: 1 input file(s) do not exist
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/tasks/car/ops/BUILD:36:13: Copying Execution Dynamic Library failed: 1 input file(s) do not exist
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/core/ops/BUILD:43:13: Copying Execution Dynamic Library failed: 1 input file(s) do not exist
Target //lingvo:trainer failed to build
Use --verbose_failures to see the command lines of failed build steps.
ERROR: D:/software/miniconda3/envs/timesfm/lingvo/lingvo/tools/BUILD:163:17 Copying Execution Dynamic Library [for tool] failed: 1 input file(s) do not exist
INFO: Elapsed time: 0.336s, Critical Path: 0.01s
INFO: 2 processes: 2 internal.
ERROR: Build did NOT complete successfullys
安装失败。由于libtensorflow_framework.so.2是Linux环境下的库文件,最直接的解决方案是在Linux环境下构建Lingvo。如果你有双系统或者可以通过WSL(Windows Subsystem for Linux)访问Linux环境,尝试在该环境中重新配置环境和构建Lingvo。
考虑到.so文件的本质和你当前使用的操作系统,转向Linux环境可能是最直接和有效的解决方案。
pip install tensorflow #tensorflow 2.6
python setup.py build
python setup.py install
由于 lingvo 0.13.1 需要tensorflow-text>2.13.0 但是win版本只有tensorflow-text2.10 whl的版本。导致安装不了。要特殊编译。 建议使用linux环境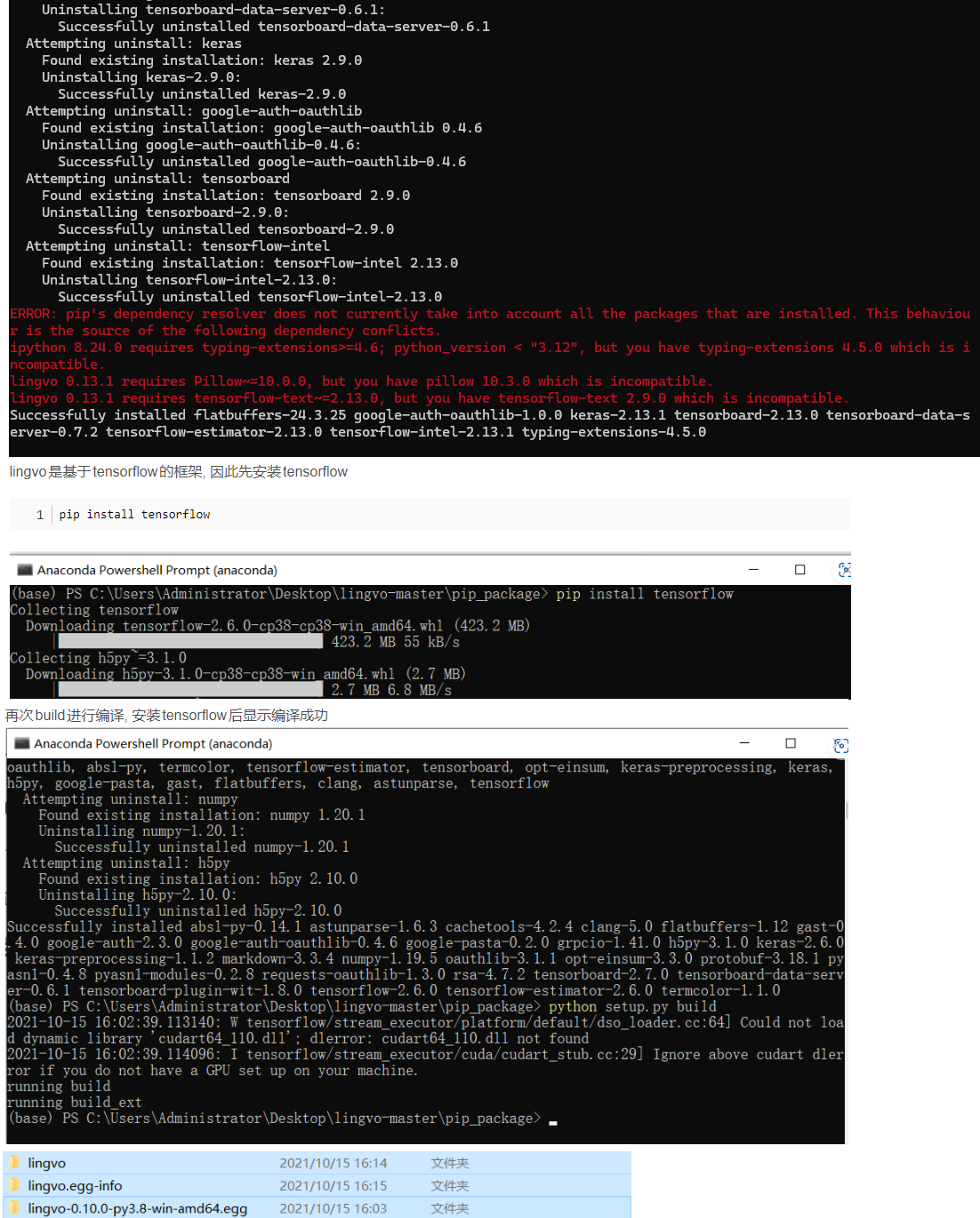
要在Windows上开启并使用Windows Subsystem for Linux (WSL)搭配Ubuntu,你可以按照以下步骤操作:
3.1 1. 启用WSL功能
打开“启用或关闭Windows功能”
:
- 按下
Win + X快捷键,然后选择“程序和功能” > “启用或关闭Windows功能”。 - 或者,直接在开始菜单搜索“启用或关闭Windows功能”并打开。
- 按下
勾选功能:在列表中找到并勾选“适用于Linux的Windows子系统”和“虚拟机平台”(WSL 2需要这个功能),然后点击“确定”。这可能需要重启计算机以使更改生效。
3.2 2. 安装Ubuntu
- 打开Microsoft Store:点击开始菜单,搜索并打开Microsoft Store。
- 搜索Ubuntu:在Microsoft Store的搜索框中输入“Ubuntu”,你会看到几个不同的Ubuntu版本,如Ubuntu 22.04 LTS、Ubuntu 20.04 LTS等。
- 选择并安装:选择你想要的Ubuntu版本,点击获取或安装按钮进行下载和安装。安装完成后,它会出现在开始菜单中。
3.3 3. 初始化Ubuntu
首次启动:从开始菜单启动刚安装的Ubuntu。首次启动时,系统会引导你设置新的Ubuntu用户账户和密码。
升级到WSL 2(如果需要)
:
- 打开PowerShell(以管理员身份运行)。
- 输入以下命令检查WSL版本并确认Ubuntu是否已经是WSL 2:
wsl -l -v - 如果不是WSL 2,可以使用以下命令将其转换为WSL 2:
wsl --set-version Ubuntu 2(将“Ubuntu”替换为你安装的Ubuntu发行版的实际名称,如果名称中有空格,需要用引号括起来)。
3.4 4. 使用Ubuntu
- 以后每次想要使用Ubuntu,只需从开始菜单启动它,你将进入一个Linux命令行界面,可以运行各种Linux命令、安装软件包、编写代码等。
3.5 5. (可选)配置Visual Studio Code集成
- 若要在Visual Studio Code中直接使用WSL中的Ubuntu作为终端和开发环境,可以安装VS Code的“Remote Development”扩展包,并通过它在VS Code内无缝访问和编辑WSL中的文件。
完成以上步骤后,你就成功地在Windows上设置了WSL并使用Ubuntu了。
安装 conda env create –file=environment.yml
问题解决。